def sum(*numbers)
s =0 for i in numbers
s += i
endreturn s
endputssum(1,2,3,4,5)
如果方法的輸入參數中有一般參數與未定長度參數:
def sum(*scores, classnumber)
s =0 for i in scores
s += i
endputs"#{classnumber}'s average score is #{s.to_f/scores.length}"endsum(100,92,93,64,85,102)
a1 =['d','a','z','k','w']print a1.sort
a2 =[[1,2,3,4,5],Array(2..6),[1,5,10]]def sum(ar)
s =0
ar.each{|item| s+=item}return s
endprint a2.sort{|a,b| sum(a)<=>sum(b)}
57
array.sort! [or] array.sort! { | a,b | block }: sort in place
a1 =['d','a','z','k','w'].sort!print a1
a2 =[[1,2,3,4,5],Array(2..6),[1,5,10]]def sum(ar)
s =0
ar.each{|item| s+=item}return s
end
a2.sort!{|a,b| sum(a)<=>sum(b)}print a2
58
array.to_a: 傳回array本身,若是array的subclass,傳回array物件
a1 =Array(1..5).to_aprint a1
59
array.to_ary: 也是傳回array本身
60
array.to_s: 傳回array本身的字串
a1 =Array(1..5).to_sprint a1
61
array.transpose: 傳回轉置矩陣
a =[Array(1..3),Array(4..6),Array(7..9)]print a.transpose
62
array.uniq: 傳回去除重複元素的array
a =Array(1..10)
b =Array(5..15)print(a+b).uniq
63
array.uniq!: uniq in place
a =Array(1..10)
b =Array(5..15)
c =(a+b)
c.uniq!print c
64
array.unshift(obj, ...): 在array前端插入元素,其他元素往後移位
a =Array(1..10)
a.unshift(11)
a.unshift(12,13)print a
a =Array(1..10)print a.values_at(1)print a.values_at(1,3,5,7,9)print a.values_at(2..6)
66
array.zip(arg, ...) [or]array.zip(arg, ...){ | arr | block }: zip
a =Array(1..5)
b =%W(a b c d e)
c =Array["Do","Re","Mi"]
d =["u","v"]
z1 = a.zip(b)
z2 = c.zip(a,b)
z3 = d.zip(a,b)
z4 =[]
b.zip(c,d){|x,y,z| z4 << "#{x}#{y}#{z}"}print z1,"\n", z2,"\n", z3,"\n", z4
s3 =%q{If we are going to have a long string,we can have a string span several lines.This is what I am talking about.}
s4 =<<ENDSYMBLEIf we are going to have a long string,we can have a string span several lines.This is what I am talking about.ENDSYMBLEputs s3
puts s4
puts"'Time is money' is any old proverb.".count('is')# check number of 'i' & 's'puts"'Time is money' is any old proverb.".count('ma-d')# m & a-d(included)puts"Time".count("^ie")# ^ => negatedputs"'Time is money' is any old proverb.".count('time','fine')# intersection of "time" & "fine" => 'i' & 'e'
19
str.crypt(other_str): 根據other_str(should be two characters long)產生str的加密hashcode
puts"xyz".crypt("cr")
20
str.delete(other_str, ...): 刪除給定字元
puts"current".delete("re")# delete 'r' & 'e'puts"current".delete("re","en")# delete 'e'=>intersection of re & enputs"current".delete("aeiou","^e")# ^e means not eputs"current".delete("tm-r")# delete t & m-r
21
str.delete!(other_str, ...): 刪除給定字元in place
c ="current".delete!("re")# delete 'r' & 'e'puts c
c ="current".delete!("re","en")# delete 'e'=>intersection of re & enputs c
c ="current".delete!("aeiou","^e")# ^e means not eputs c
c ="current".delete!("tm-r")# delete t & m-rputs c
22
str.downcase: 大寫變小寫
puts"Time Is Money".downcase
23
str.downcase!: 大寫變小寫in place
t ="Time Is Money".downcase!puts t
24
str.dump: 傳回包含逸出字的字串
puts"\tTime\n Is \"Money\"".dump
25
str.each_byte { |fixnum| block }: 針對字串中每一byte
"Time is money.".each_byte{|i| puts"" << i}
s =""for i in"Time is money.".each_byteputs s << i
end
puts"Time is money".gsub("Time","Everything")puts"Time is money".gsub(/[aeiou]/,'@')
puts"Time is money".gsub(/([aeiou])/,'<\1>')
puts"Time is money".gsub(/./){|s| s.ord.to_s+' '}#s.ord傳回codepointputs"Time is money".gsub(/([mn])/,"m"=>"M",'n'=>"N")
print"Time is money".scan(/.../)
print"Time is money".scan(/(...)/)
print"Time is money".scan(/(...)(...)/)
print"Time is money".scan(/m./)
print"Time is money".scan(/\w+/)
"Time is money".scan(/\w+/){|match| putsmatch.upcase}
puts"Time is money".slice(3)puts"Time is money".slice(3,9)puts"Time is money".slice(3..9)puts"Time is money".slice(/[aeiou]./)
t ="Time is money"
t["is"]="can be"puts t
t ="Time is money"puts t.slice!(3...9)puts t
68
str.split(pattern = $, [limit]): split
print"Time is money".splitprint"Time is money".split(' ')print"Time is money".split('m')print"Time is money".split(/[aeiou]/)
print"Time is money".split(//)
print"Time is money".split(//,3)
print"Time is money".split(%r{\s*})
puts"Time is money".sub(/[aeiou]/,"#")
puts"Time is money".sub(/([aeiou])/,'<\1>')
puts"Time is money".sub(/./){|s| s.ord.to_s+" "}puts"Time is money".sub(/(?<whatever>[aeiou])/,'*\k<whatever>*')
75
str.sub!(pattern, replacement) [or]str.sub!(pattern) { |match| block }: 替換子字串in place
s ="Time is money"
s.sub!(/[aeiou]/,"#")
puts s
76
str.succ [or] str.next: 傳回str的successor
puts"Time is money.".succputs"Ver2.0".nextputs"<<Champion>>".succputs"100zzz".succputs"zzz999".succputs"+++".next
77
str.succ! [or] str.next!: 傳回str的successor in place
s ="Time is money"
s.succ!puts s
t ="***"
t.next!
puts t
print'single quote',"\t",'single quote'.class,"\n"print"double quote","\t","double quote".class,"\n"print%(parenthesis),"\t",%(parenthesis).class,"\n"print%[bracket], "\t", %[bracket].class,"\n"print%{brace}, "\t", %{brace}.class,"\n"print%|vertical bar|,"\t",%|vertical bar|.class,"\n"# any other symbol -> *, !, @, #, $, ^, & ->試了好像都可以,不過似乎不需要print%&any other symbol&,"\t",%&any other symbol&.class,"\n"# 使用'<<文字'與'文字'作為前後符號
s =<<WhateverThis is a string thatcorssing several lins......Whateverputs s, s.class
甚至可以這樣做:
print <<"FRUIT", <<"BAR"# stackfirst fruit......
Apple
Banana
Pear
FRUIT
second bar......
Horizontal bar
Vertical bar
BAR
h =Hash.new{|h,k| h[k]= k.to_i*k.to_i}
p = h.default_proc
a ={}
p.call(a,"2")
p.call(a,"3")print a
13
hash.default_proc = proc_obj or nil: 設定hash的default_proc為一個proc物件(proc_obj)或nil
h =Hash.new
h.default_proc= proc do |hash,key|
hash[key]=key+keyend# or h.default_proc = proc {|hash, key| hash[key] = key+key} 來建立一個小函數(proc物件)
h[3]
h["hi"]print h
h ={one: 1,two: 2,three: 3}
h.each{|key,value| printkey,"->",value,"\n"}
a =[]
h.each_pair{|key,value| a << key << value}print a,"\n---------------\n"for k,v in h.each# 傳回enumeratorprint k,"<->",v,"\n"endfor k,v in h.each_pair# 傳回enumerator
a << k << v
endprint a
18
hash.each_key { |key| block }: 針對每一個key
h ={one: 1,two: 2,three: 3}
h.each_key{|key| putskey}forkeyin h.each_keyprintkey,"->",h[key],"\n"end
19
hash.each_value { |value| block }: 針對每一個value
h ={one: 1,two: 2,three: 3}
h.each_value{|value| putsvalue}forvaluein h.each_valueputsvalueend
20
hash.empty?: 檢察hash是否內容為空,return boolean
h ={one: 1,two: 2,three: 3}puts h.empty?
h1 =Hash.new# or h1={}puts h1.empty?
21
hash.eql?(another_hash): 檢查hash與another_hash是否相等
h ={one: 1,two: 2,three: 3}
h1 =Hash.new
h2={}puts h.eql?(h1), h1.eql?(h2)
h ={one: 1,two: 2,three: 3}puts h.fetch(:one)puts h.fetch(:five,"200")# if key cannot be foundputs h.fetch(:five){|el| "cannot find key = #{el}"}# if key cannot be foundprint h
h ={"one"=> 1,"two"=> 2,"three"=> 3,"four"=> 4}
g = h.transform_keys {|key| key.to_sym}
f = h.transform_keys.with_index{|key,index| "#{key}.#{index+1}"}
e = g.transform_keys(&:to_s)#等同 e = g.transform_keys {|key| key.to_s}puts e, f, g, h
53
hash.transform_keys! {|key| block} [or] hash.transform_keys!.with_index {|key, index| block}: 轉換keys in place
h ={"one"=> 1,"two"=> 2,"three"=> 3,"four"=> 4}
h.transform_keys! {|key| key.to_sym}puts h
h.transform_keys!(&:to_s)puts h
h.transform_keys!.with_index{|key,index| "#{key}.#{index+1}"}puts h
hash.transform_values! {|value| block} [or] hash.transform_values!.with_index {|value, index| block}: 轉換values in place
h ={"one"=> 1,"two"=> 2,"three"=> 3,"four"=> 4}
h.transform_values!{|value| value*value}puts h
h.transform_values!(&:to_s)puts h
h.transform_values!.with_index{|value,index| "#{value}.#{index}"}puts h
def funcname #函數funcnameyield#使用yield關鍵字呼叫block來執行block中的codeend
funcname {# 與函數同名的block for _ in1..3puts"codes of block"end}
也可以給block加上輸入參數:
def funcname #函數funcnameyield("Tom",18)#使用yield呼叫block來執行block中的codeend
funcname {|name, age| puts"#{name} is #{age} years old."}
或是
def funcname #函數funcnameyield(10)#使用yield呼叫block來執行block中的codeyield(20)end
funcname do |n|
sum=0 for i in1..n
sum+= i
endputssumend
跟函數類似,最後的結果可做為傳回值(不過不可以使用return),例如:
def prime(alist)
result =[]
alist.each do |i|
result << i ifyield(i)end
result
end
k = prime([*(2..100)]) do |x| #[*(2..100)] 等同於 (2..100).to_a 或 Array(2..100)
isPrim =true for i in2..(x-1) if x%i ==0
isPrim =falsebreakendend
isPrim
endprint k
我們可以使用block_given?函數來判斷是否有給block再來決定如何進行,例如:
def funcname
if block_given?
yieldelseputs"No block given"endend
funcname #呼叫函數funcname
funcname {puts"Inside the block"}
func = lambda do |n| # This is a Proc objectsum=0(1..n).each{|i| sum+= i}returnsumenddef accumulation(n, proc) # Proc func as an argumentputs"1+...+#{n} = #{proc.call(n)}"#puts proc.call(n)end
accumulation(10, func)# Proc func as an argument
根據這個方式,我們可以將之前的質數函數改寫如下:
def primes(alist, proc)
result =[]
alist.each do |i|
result << i if proc.call(i)end
result
end
k = lambda do |x| #check if x is a prime?
isPrim =true for i in2..(x-1) if x%i ==0
isPrim =falsebreakendend
isPrim
endprint primes([*2..100], k)
不過事實上可以寫成如下:
def primes(alist, &proc)
result =[]
alist.each do |i|
result << i if proc[i]# 等同proc.call(i) or proc.call iend
result
end
k = primes([*2..100]) do |x| #check if x is a prime?
isPrim =true for i in2..(x-1) if x%i ==0
isPrim =falsebreakendend
isPrim
endprint k
currentTime1 =Time.new# Time object
currentTime2 =Time.now# Time objectputs currentTime1, currentTime2.inspect#Time object & String
若欲取得時間的各部分,方式如下:
now=Time.nowputsnow.year,now.month,now.day,now.hour,now.min,now.sec,now.usec,now.zone#usec means microseconds(999999)putsnow.wday,now.yday# day of week and day of year
def id=(newId)
if newId < 0puts"Age has to be positive."else
@id = newId
endend
現在再使用
s.name="Mary"
s.id =-2
s.department ="LM"puts s
便會看到顯示的錯誤訊息了。至於要設定方法的存取權限,使用
public: default
protected: can be invoked only by objects of the defining class and its subclasses
private: cannot be accessed or viewed from outside the class. Only the class methods can access it.
使用方式則例如:
class AccessMethod
def publicM
"This is a public method"end
protected
def protectedM
"This is a protected method"end
private
def privateM
"This is a private method"endend
acc = AccessMethod.newputs acc.publicM
#puts acc.protectedM ## protected method `get2' called (NoMethodError)#puts acc.privateM ## private method `privateM' called (NoMethodError)
可以看到除了public方法之外都無法呼叫。宣告方法的accessibility還可以如下:
class AccessMethod
def publicM
"This is a public method + "+ protectedM +" + "+ privateM
# protect method can also be called: self.protectedM or send(:protectedM) or self.send(:protectedM)# privated method called can also be: self.send(:privateM)end
protected
def protectedM
"(protected method + "+self.send(:privateM)+")"end
private
def privateM
"private method"end# protected :protectedM# private :privateMend
acc = AccessMethod.newputs acc.publicM
puts acc.send(:protectedM)puts acc.send(:privateM)
If it walks, quacks and swims like a duck then it must be a duck. In other words if an object has the correct method then it must be the correct object. Duck typing judges two types to be equivalent if they both have same methods.
因為ruby沒有像Java的interface,duck type讓我們可以讓有相同方法的class變成相同型態。例如:
class C1
def mOne
puts"mOne in C1"endendclass C2
def mOne
puts"mOne in C2"endend
arrayC =[C1.new, C2.new]
arrayC[0].mOne # mOne in C1
arrayC[1].mOne # mOne in C2
這樣的做法在Java顯然是不可行的。再看一例:
class Car
attr_accessor :engine, :tires, :airConditionerdef initialize(engine, tires, airConditioner)
@engine = engine
@tires = tires
@airConditioner = airConditioner
enddef routineService(staffs)
staffs.each do |staffs|
staffs.exam(self)endendendclass EngineMechanic
def exam(car)
puts"exam #{car.engine}"endendclass TiresMechanic
def exam(car)
puts"exam #{car.tires}"endendclass ACMechanic
def exam(car)
puts"exam #{car.airConditioner}"endend
car = Car.new("engine brand","tires brand","AC brand")
em = EngineMechanic.new
tm = TiresMechanic.new
am = ACMechanic.new
car.routineService([em, tm, am])
class Car
attr_accessor :wheels, :seatsdef initialize(wheels, seats)
@wheels, @seats = wheels, seats
enddef to_s
"A #{@wheels} wheels car with #{@seats} seats"endendclass Bike < Car
attr_accessor :maxSpeeddef initialize wheels, seats, maxSpeed
super wheels, seats
@maxSpeed = maxSpeed
enddef ride
%Q(Riding a bike with #{@wheels} wheels and max speed is #{@maxSpeed})enddef to_s
"A #{@wheels} wheels car with #{@seats} seats and max speed #{maxSpeed} kph"endend
bike = Bike.new(2,2,35)puts bike.ride
puts bike
class Car
attr_accessor :wheels, :seatsdef initialize(wheels, seats)
@wheels, @seats = wheels, seats
enddef to_s
"A #{@wheels} wheels car with #{@seats} seats"endendclass MyBenz < Car
def price
"Expensive..."endendclass MyMaserati < Car
def price
"Even more expensive..."endend
mb = MyBenz.new4,5
mm = MyMaserati.new4,5puts mb.price # Expensive...puts mm.price # Even more expensive...
Open class
這是一個特別的用法,先看下例,首先將以下class加到剛剛的例子:
class Bike
def bikeColor(color)
"I hava a #{color} bike."endend
然後執行改為:
bike = Bike.new(2,2,35)puts bike.bikeColor("blue")# I hava a blue bike.puts bike.ride # Riding a bike with 2 wheels and max speed is 35
class Bike
def bikeColor(color)
"I hava a #{color} bike."enddef ride
%Q(Riding a bike so hard on the field...)endend
bike = Bike.new(2,2,35)puts bike.bikeColor("blue")# I hava a blue bike.puts bike.ride # Riding a bike so hard on the field...
而若是也想要使用原來的方法,可以將其更名:
class Bike
def bikeColor(color)
"I hava a #{color} bike."end
alias_method :oride, :ridedef ride
%Q(Riding a bike so hard on the field...)endend
bike = Bike.new(2,2,35)puts bike.bikeColor("blue")# I hava a blue bike.puts bike.oride # Riding a bike with 2 wheels and max speed is 35puts bike.ride # Riding a bike so hard on the field...
這樣的形式稱為開放類別,讓我們可以修改之前已存在但是不符合我們需要的方法,甚至程式內定的方法:
classStringdef hi
"Hello, #{self}. How are you?"endendputs"Tom".hi # Hello, Tom. How are you?puts"Mary".hi # Hello, Mary. How are you?
或是
classIntegerdef days
self*24*60*60enddef ago
Time.now-selfendendputs3.days.ago #2019-07-12 11:32:42 +0800
module Salary
attr_accessor :basedef initialize(base)
@base = base
enddef pay(bonus)
@base+bonus
endendmodule PersonalInfo
attr_accessor :name, :genderdef initialize(name, gender)
@name=name
@gender = gender
endendclass Employee
include Salary
include PersonalInfo
def initialize(n, gender, base, bonus)
@bonus = bonus
PersonalInfo.instance_method(:initialize).bind(self).call(n,gender)
Salary.instance_method(:initialize).bind(self).call(base)enddef to_s
"#{name} is a #{gender} and salary is #{pay(@bonus)}"endendclass InternationalEmployee < Employee
end
em1 = Employee.new("Tom","male",22000,20000)puts em1 # Tom is a male and salary is 42000
em2 = InternationalEmployee.new("Mary","female",22000,25000)puts em2 # Mary is a female and salary is 47000
module Customer
attr_accessor :namedef initialize(name, x, y)
@name=name
@x = x
@y = y
enddef to_s
"#{@name} at (#{@x}, #{@y})"endendmodule Cargo
def item(i)
puts"Sending item: #{i}"enddef value(v)
puts"The value of the item is #{v}"endendclass Delivery
include Customer
include Cargo
end
de = Delivery.new("Tom",1,10)puts de # Tom at (1, 10)
de.item("book")# Sending item: book
de.value(100)# The value of the item is 100
beginprint"How old are you?"
age =gets.to_i## gets can receive the value inputed from keyboard if age < 0raise"Negative Age Exception."endputs"So you are #{age} years old."rescue## 當錯誤發生時執行puts"Age cannot be negative. Please reenter:"
age =gets.to_iputs"So you are #{age} years old."else## 當不需要rescue時執行puts"Perfect. You are doing a good job."ensure## 一定會執行puts"See you."end
beginprint"How old are you?"
age =gets.to_i## gets can receive the value inputed from keyboard if age < 0raise"Negative Age Exception."endputs"So you are #{age} years old."rescue## 當錯誤發生時執行puts"Age cannot be negative. Please reenter:"retryelse## 當不需要rescue時執行puts"Perfect. You are doing a good job."ensure## 一定會執行puts"See you."end
beginprint"How old are you?"
age =gets if age.scan(/\D/)==["\n"]or age.scan(/\D/)==["-","\n"]
age = age.to_ielseraiseTypeError,"Need numbers"end if age < 0raiseArgumentError,"Age cannot be negative"end if age > 150raise"Seriously?"endputs"So you are #{age} years old."rescueTypeError=> e
puts"Error: #{e}"retryrescueArgumentError=> e
puts"Nagative age error: #{e}"retryrescueStandardError=> e # or: rescue => eputs"#{e} Are you truly #{age} years old?"elseputs"Perfect. You are doing a good job."ensureputs"See you."end
class KiddingException < StandardErrordef initialize(message, others) # others is customized variablesuper(message)
@others = others
enddef more
@others
endendbeginprint"How old are you?"
age =gets if age.scan(/\D/)==["\n"]or age.scan(/\D/)==["-","\n"]
age = age.to_ielseraiseTypeError,"Need numbers"end if age < 0raiseArgumentError,"Age cannot be negative"end if age > 150and age <=200raise"Seriously?"end if age > 200raise KiddingException.new("Are you kidding me?","I don't believe it.")endputs"So you are #{age} years old."rescueTypeError=> e
puts"Error: #{e}"retryrescueArgumentError=> e
puts"Nagative age error: #{e}"retryrescue KiddingException => e
puts e, e.more
rescueStandardError=> e # or: rescue => eputs"#{e} Are you truly #{age} years old?"elseputs"Perfect. You are doing a good job."ensureputs"See you."end
ifFile.exist?"test.txt"# is exists?file=File.open("test.txt","r")puts"test.txt is open."endputsFile.atime"test.txt"# last access timeputs"Last access time is #{file.atime}"# last access timeputsFile.ctime"test.txt"# directory change time(not the file itself changed)print"The ctime >>> ",file.ctime,"\n"# directory change time(not the file itself changed)putsFile.mtime"test.txt"# file modification timeprint"The mtime >>> ",file.mtime,"\n"# file modification timeputsFile.birthtime "test.txt"# time of birthputsfile.birthtime # time of birthfile.close
關於檔案名與路徑:
ifFile.exist?"test.txt"# is exists?file=File.open("test.txt","r")puts"test.txt is open."endputsFile.extname(file)# filename extension >>> .txtprint"The base name >>> ",(File.basenamefile),"\n"# the base name >>> test.txtputsFile.basenamefile,File.extname(file)# filename without extensionputsFile.basenamefile,".txt"# filename without extension, same to aboveputsFile.basenamefile,".*"# filename without extension, same to aboveprint"file path >>> ",file.path," >>> ",file.to_path,"\n"# the pathname to create fileputsFile.dirname"E:/NKFUST/www/Ruby/test.txt"# return the directory name >> E:/NKFUST/www/RubyputsFile.absolute_path("test.txt")# return absolute pathputsFile.realdirpath "test.txt"# return the real(absolute) pathnameputsFile.realpath "test.txt"# return the real(absolute) pathnameprintFile.split("E:/NKFUST/www/Ruby/test.txt")# ["E:/NKFUST/www/Ruby", "test.txt"]file.close
關於檔案本身資訊與狀態:
ifFile.exist?"test.txt"# is exists?file=File.open("test.txt","r")puts"test.txt is open."endputsFile.file?"test.txt"# if file exists and is a regular fileputsFile.readable?"test.txt"# if file is readableputsFile.writable?"test.txt"# if file is writableputsFile.size"test.txt"# file sizeputsfile.size# file sizeputsFile.size?"test.txt"# file size, if file does not exist or has zero size, return nilputsFile.zero?"test.txt"# if file exists and size = 0file.closeFile.delete"test.txt"# delete the corresponding file >>> cannot delete while open, close first
IO
除了上列的方法,也可以直接使用IO物件來操作,例如:
Read:
putsIO.binread"test.txt"# read the whole file content, CAN USE READ TO REPLACE BINREADputsIO.binread"test.txt",20# read the first 20 bytes(length)putsIO.binread"test.txt",20,10# read 20 bytes(length) starts from 10 bytes(offset)printIO.readlines"test.txt"# read all lines, return an arrayIO.readlines("test.txt").each{|line| print">>>", line}IO.readlines("test.txt", sep=",").each{|line| print">>>", line}# use , as seperatorIO.readlines("test.txt", limit=8).each{|line| print">>>", line}# read every 8 bytesIO.foreach"test.txt" do |line| # or: IO.foreach("test.txt") {|line| puts line}puts line
end
binread等同於read。
Write:
putsIO.binwrite("test.txt","Infomation that are going to write into the file")# return the size of infomation to writeputsIO.binwrite("test.txt",">>>",offset=10)# return the size of infomation to write# if offset is not given, the file is truncated. # Otherwise, write new information starts from offset(replace the old content)
IO.copy_stream("test.txt","test1.txt")# copy content from source to destinationIO.copy_stream("test.txt","test1.txt",20)# copy specific length of content (20 bytes) from source to destination

 點擊打開,可以直接在其中輸入Ruby的指令,例如:
點擊打開,可以直接在其中輸入Ruby的指令,例如:
 這個方式在練習時或是要確認某函數的運作相當方便快速,可多加利用。
這個方式在練習時或是要確認某函數的運作相當方便快速,可多加利用。
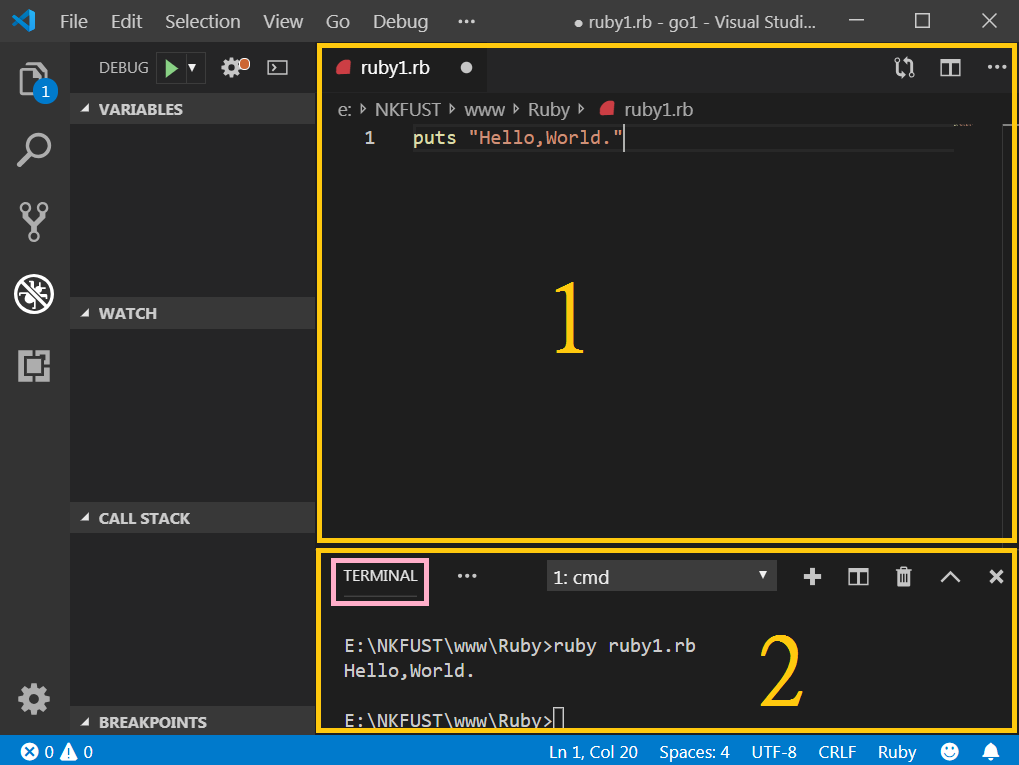 在區塊1中是編寫程式碼的地方,下方區塊2選擇TERMINAL,就是DOS了。接下來輸入
在區塊1中是編寫程式碼的地方,下方區塊2選擇TERMINAL,就是DOS了。接下來輸入
 使用puts會顯示=>nil表示傳回空,而使用p傳回10。
若是有以下程式碼:
使用puts會顯示=>nil表示傳回空,而使用p傳回10。
若是有以下程式碼:
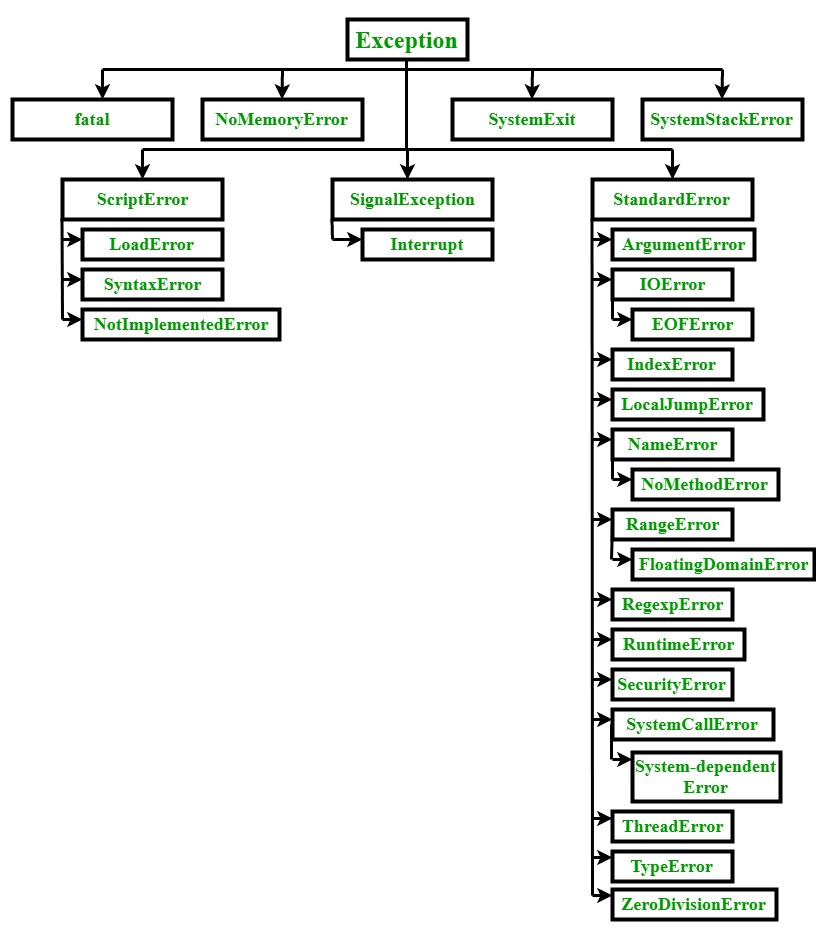 其中有些是常用的,所以如果我們的程式碼會出現超過一個的錯誤,要如何處理?
其中有些是常用的,所以如果我們的程式碼會出現超過一個的錯誤,要如何處理?